Our Project
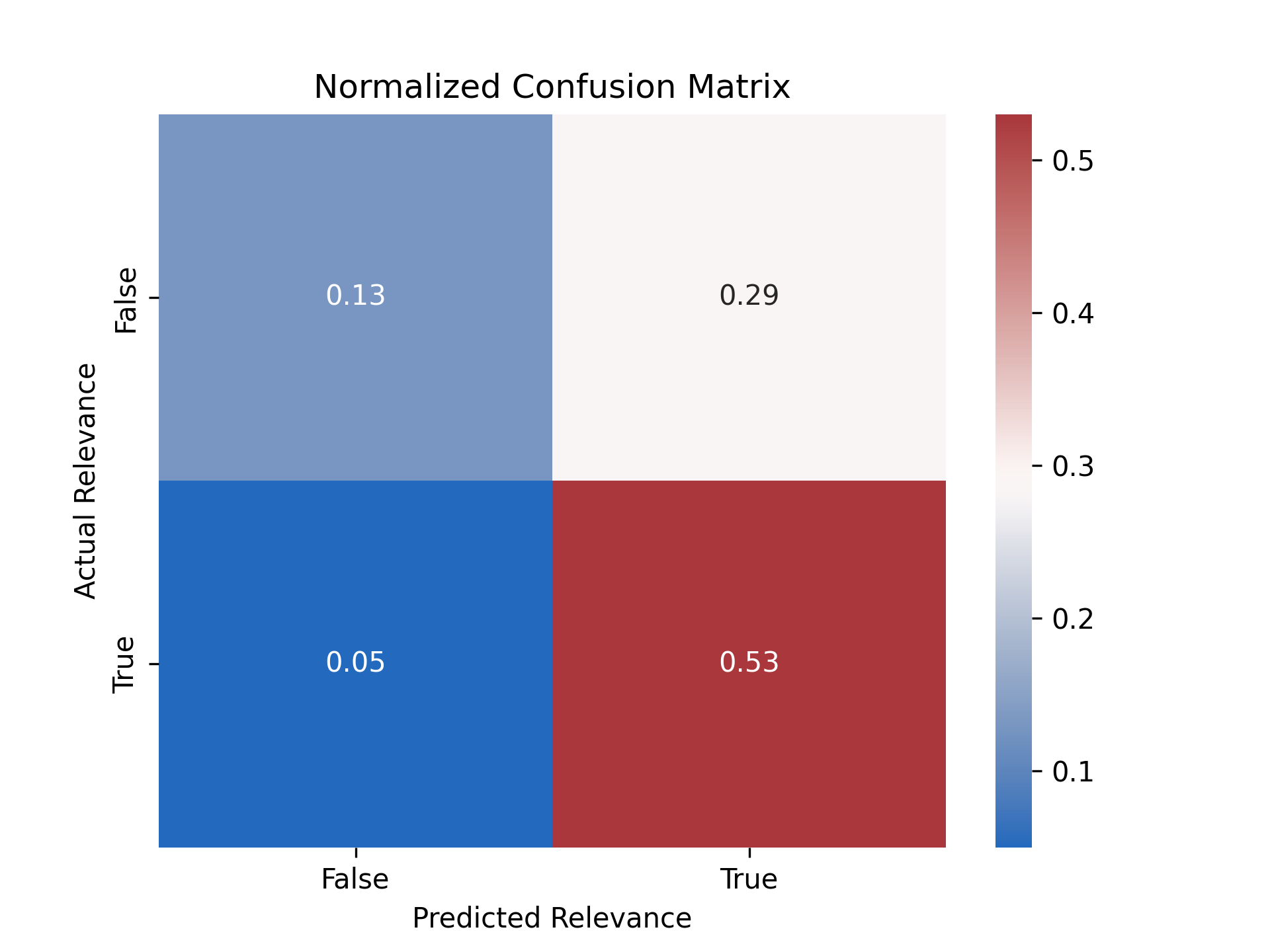
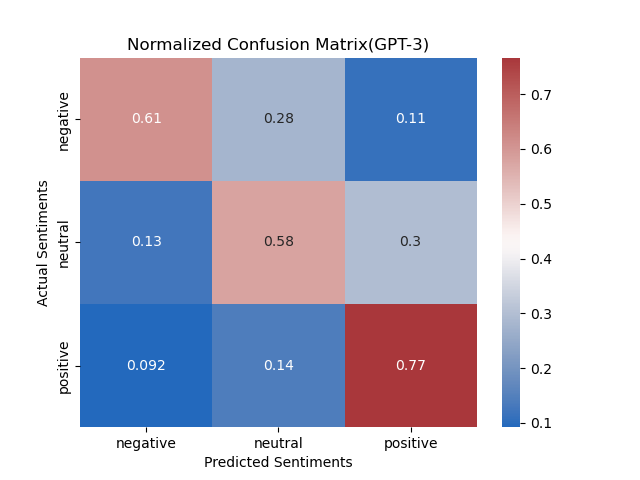
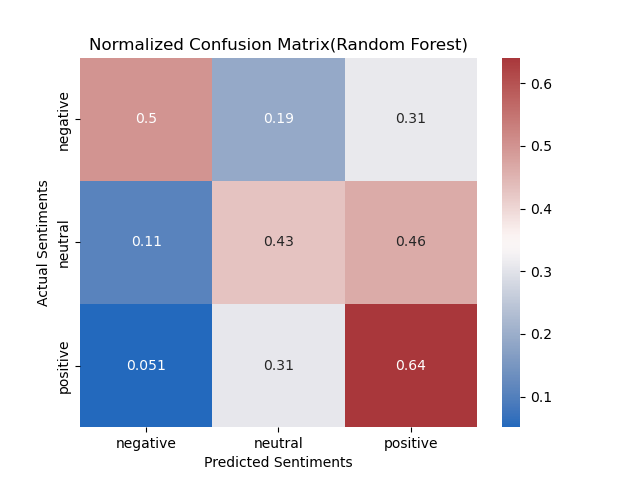
The application of LLMs to this particular topic generated measures that fell short of our
expectations, and of our Quarter 1 results. Despite continuous engineering of the prompt, we
were not able to match our original statistics in classifying relevance nor achieve high
accuracy in classifying sentiment; however, the process of using an LLM like GPT-3 revealed
clearly that these tools definitely have their place in this field.
In conversing with the UCSD China Data Lab over the course of the last 10 weeks, our work has
been helpful in determining whether they will move forward with using LLMs throughout the future
stages of their Twitter analysis projects.
Limitations & Future
Looking at the overall performance of the GPT-3 language models, and even at the supervised ML
pathways from earlier, it's easy to see that this is a difficult task no matter what tools we
use. Human interpretation of text is so influenced by preexisting biases, contexts, and other
factors that cannot be modeled, and the strange Internet-affected language of Twitter only
contributes to this further.
Because of LLMs' ability to comprehend text in its own context, outside the purview of 'trainign
data', it is worth considering shifting away from a simple classification & sentiment analysis,
and to utilize the full power of these models for deeper textual analysis.
The Models
Large Language Models are undoubtedly the future of language modeling and analysis. Their
incredible power, ease-of-use, and high quality outputs put them far ahead of any other
traditional NLP methodology. However, that does not mean simply tossing out what's been done
before and trusting GPT-3 to always get the solution. As our project shows, GPT-3 is not always
ready to bridge the gap resulting from natural differences in human interpretation and context.
Subject matter expertise and domain knowledge are and will remain absolutely key to getting the
best out of these models.











{kind=link}